네이버뉴스 스크래핑!
저번시간에 배운 것들을 토대로 네이버의 종류별 뉴스부분을 스크래핑한다

원래는 번개장터나 중고 물품거래사이트에서 lg그램을 검색하면 나오는 페이지들을 스크래핑하려했다
하지만 이렇게 거래 또는 보안을 엄격하게 걸어놓은 사이트들은 스크래핑이 되지 않는것같았다
배운대로 6단계에 걸쳐서 시행해 보았다
1. 먼저 requests와 BeautifulSoup의 패키지를 다운받고 네이버 URL을 가져왔다
import requests
from bs4 import BeautifulSoup
URL = 'https://www.naver.com/'2. 마지막 페이지로 쓰일 것은 이번엔 페이지 번호가 아닌 분류명(리빙,푸드,스포츠,자동차 등등 28개의 종류들)
div태그 중 class명이 "rolling-container"인 것을 찾고 그중 li태그로 이루어진 모든것을 리스트화 시켰다
반복문을 통해 분류명이 텍스트형식으로 리스트에 들어가도록 했다 (그 이유는 get_text함수는 리스트 자체를 못 쓴다)
새로운 리스트에 텍스트를 담아주면 마지막 페이지 수는 리스트의 길이로 체크했다
def get_last_pages():
result = requests.get(URL)
s = BeautifulSoup(result.text, "html.parser")
links = s.find("div",{"class":"rolling-container"}).find_all("li")
page=[] #새로운 리스트
for i in range(len(links)): #리스트 자체를 get_text하지못하기때문에 반복문을 사용
page.append(links[i].get_text(strip="\n"))
max_page = len(page)
return max_page
3. 요소로는 제목과 링크를 가져오기로 했다
def extract_job(html):
result = requests.get(URL)
s = BeautifulSoup(result.text, "html.parser")
title_r = s.find("span",{"class": "td_t"})
title=title_r.get_text()
link= s.find("li",{"class":"tl_default"}).find("a")["href"]
return {
"title": title,
"link": link
}4. 모든 페이지를 찾고 요소들을 리스화 했다
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
print(f"Scrapping Indeed: Page: {page}")
result = requests.get(URL)
s = BeautifulSoup(result.text, "html.parser")
results = s.find_all("li", {"class": "tl_default"}) #사실 이 부분만 빼면 나머지는 거의 같다
job = extract_job(result)
jobs.append(job)
return jobs그리고 깔끔한 마무리~
def get_jobs():
last_page=get_last_pages()
jobs=extract_jobs(last_page)
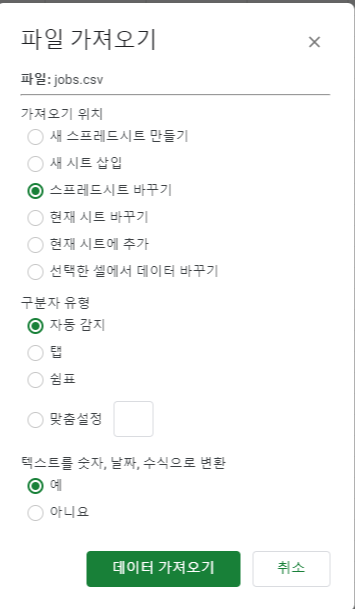
return jobs5. CSV파일로 만들기와 6.스프레드시트에 불러오기는 https://jejehoon.tistory.com/15를 참고하면 된다
완성!!!!!!!!!

이것도 따라한거라고 생각하지만 막상 해보니 막히는 부분이 생기면서 시간이 엄청 지체되었다
React JS로 날씨앱 만들기는 따라만하고 직접 다시 만들어보지는 않았었다
복습을 통해서 다시 떠올리고 또 새로운걸 알아가는 계기가 되었다 좋았다
다음은 Go언어!

'노마드코더스 아카데미 > 파이썬으로 웹스크래퍼 만들기' 카테고리의 다른 글
| 파이썬 웹스크래핑with nomad coders[10]끝!!! (0) | 2020.03.09 |
|---|---|
| 파이썬 웹스크래핑with nomad coders[9] (0) | 2020.03.09 |
| 파이썬 웹스크래핑with nomad coders[8] (0) | 2020.03.08 |
| 파이썬 웹스크래핑with nomad coders[7] (0) | 2020.03.08 |
| 파이썬 웹스크래핑with nomad coders[6] (0) | 2020.03.08 |