예시) superAdd함수에 들어있는 인자(2,3,4,5,7,9)의 개수 6개만큼 numbers를 출력한다 ≒forEach( ) in javascript
func superAdd(numbers ...int) int{
for number := range numbers{ //반복할 횟수는 numbers의 개수
fmt.Println(number) //반복될 내용
}
return 1
}
func main(){
superAdd(2,3,4,5,7,9) //numbers의 개수는 6개
}
실행결과를 보면
이렇게 나오게 되는데 배열 요소의 개수만큼 자동으로 index값을 받게 되어서라고 한다
array(배열)과 slice(슬라이스: 융통성 있는 배열?)에서 range반복문은 index값과 배열 안의 값을 생성한다(index먼저 생성)
index를 보기 싫다면 for의 변수 중 처음은 무시하고( _ 언더바 사용 ) 두 번째 것을 입력하면 된다
이렇게
func superAdd(numbers ...int) int{
for _,number := range numbers{
fmt.Println(number)
}
return 1
}
func main(){
superAdd(2,3,4,5,7,9)
(2) i 사용
C언어와 비슷하다
꼭 i만 써야 되는 것은 아니다(하지만 아마도 수는 안될 것이다)
형태: for i:=0; i <범위(대신 수 형태여야 함); i++{
반복할 내용
}
(3) 총합 구하기 예제
package main
import (
"fmt"
)
func superAdd(numbers ...int) int {
total := 0 //총합이 되어줄 친구 반복문 밖에 있어야함
for _, number := range numbers {//index는 보기싫어서 _로 무시
total = number + total //total변수에 각각의 수를 더해주기
}
return total
}
func main() {
result := superAdd(2, 3, 6, 7, 9, 10)
fmt.Println(result)
}
//결과 37
요약
1. for만 사용(for in, forEach 없음)
2.range는 배열에선 index값을 먼저 생성한다
3.i 같은 변수로도 범위를 구할 수 있다
2. if ~ else, switch~case
1. if ~ else
1) 다른 언어들과 다르게 ( )이나 :이 필요 없다
2) VScode에서 제공하는 extention return값을 주면 else를 쓸 필요 없다
3) if문을 쓰는 도중에 변수를 생성할 수 있다(무엇을 위한 변수인지 알아보기 쉬움)
if koreanAge := age + 2; koreanAge < 18 { //(),:필요없이 조건 바로적음 //koreanAge := age + 2; if문을 쓰는 도중에 변수만들기
return false
}
return true //else{ return true} 였을텐데 return true만 적어도 실행가능
else if 조건을 추가할 때 쓰임
if 조건{
} else if 조건{
} else {
}
2. switch/case
1) C나 javascript와 많이 비슷하다(파이썬은 switch를 사용하지 않음)
2) if~else와 마찬가지로 쓰는 도중에 변수를 생성할 수 있다
3) else if를 도배할 필요 없이 case로 짧게 짧게 쓸 수 있다
package main
import (
"fmt"
)
func canIdrink(age int) bool {
switch koreanAge= age+2; koreanAge { //switch문 도중 변수 선언 가능
case age < 18: //만약 if문을 썼다면 else if로 도배될 것을 case로 짧게 짧게
return false
case age ==18:
return true
}
return false
}
func main() {
result := canIdrink(18)
fmt.Println(result)
}
원래는 번개장터나 중고 물품거래사이트에서 lg그램을 검색하면 나오는 페이지들을 스크래핑하려했다
하지만 이렇게 거래 또는 보안을 엄격하게 걸어놓은 사이트들은 스크래핑이 되지 않는것같았다
배운대로 6단계에 걸쳐서 시행해 보았다
1. 먼저 requests와 BeautifulSoup의 패키지를 다운받고 네이버 URL을 가져왔다
import requests
from bs4 import BeautifulSoup
URL = 'https://www.naver.com/'
2. 마지막 페이지로 쓰일 것은 이번엔 페이지 번호가 아닌 분류명(리빙,푸드,스포츠,자동차 등등 28개의 종류들)
div태그 중 class명이 "rolling-container"인 것을 찾고 그중 li태그로 이루어진 모든것을 리스트화 시켰다
반복문을 통해 분류명이 텍스트형식으로 리스트에 들어가도록 했다 (그 이유는 get_text함수는 리스트 자체를 못 쓴다)
새로운 리스트에 텍스트를 담아주면 마지막 페이지 수는 리스트의 길이로 체크했다
def get_last_pages():
result = requests.get(URL)
s = BeautifulSoup(result.text, "html.parser")
links = s.find("div",{"class":"rolling-container"}).find_all("li")
page=[] #새로운 리스트
for i in range(len(links)): #리스트 자체를 get_text하지못하기때문에 반복문을 사용
page.append(links[i].get_text(strip="\n"))
max_page = len(page)
return max_page
3. 요소로는 제목과 링크를 가져오기로 했다
def extract_job(html):
result = requests.get(URL)
s = BeautifulSoup(result.text, "html.parser")
title_r = s.find("span",{"class": "td_t"})
title=title_r.get_text()
link= s.find("li",{"class":"tl_default"}).find("a")["href"]
return {
"title": title,
"link": link
}
4. 모든 페이지를 찾고 요소들을 리스화 했다
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
print(f"Scrapping Indeed: Page: {page}")
result = requests.get(URL)
s = BeautifulSoup(result.text, "html.parser")
results = s.find_all("li", {"class": "tl_default"}) #사실 이 부분만 빼면 나머지는 거의 같다
job = extract_job(result)
jobs.append(job)
return jobs
그리고 깔끔한 마무리~
def get_jobs():
last_page=get_last_pages()
jobs=extract_jobs(last_page)
return jobs
원래 title요소를 찾을 때 했었지만 20페이지 모두 매번 볼 수 없었기 때문에 니꼬쌤은 다른 함수로 옮겼다
def extract_jobs(last_page): #모든데이터 추출하는 함수
jobs = [] #빈 리스트 jobs만들기
for page in range(last_page): #마지막페이지까지 아래를 실행하는 반복문
print(f"Scrapping Indeed: Page: {page}") #되는지 안되는지 보기위한 출력문장
result = requests.get(f"{URL}&start={page*Limit}")
s = BeautifulSoup(result.text, "html.parser")
results = s.find_all("div", {"class": "jobsearch-SerpJobCard"})#모든 페이지 jobcard가져오기
for result in results:
job = extract_job(result)#제목,회사명,위치,링크추출하는 함수 실행
jobs.append(job) #리스트에 넣기
return jobs #반환값
마지막으로 get_jobs함수를 만들어 나머지 세 개의 함수를 잘 정리했다
def get_jobs():
last_page=get_last_pages()
jobs=extract_jobs(last_page)
return jobs
인디드는 끝!!
스택오버플로우는 이와 같이 반복 진행하므로 생략한다(물론 약간씩 다른 부분도 있어서 영상을 보는 것이 훌륭하다)
CSV란? 콤마(Comma)로 데이터들을 구분한 파일이라는 뜻 엑셀이나 스프레드시트에 사용할 수 있다
인디드나 스택오버플로우와 마찬가지로 save.py를 만들어 코드를 작성한다
(main.py에는 오직 각 모듈에서 나오는 함수들만 있도록 깔끔하게)
먼저 save.py에서 파이썬에 내장된 CSV모듈을 import 해준다
(CSV모듈을 import 해주면 csv파일을 작성할 수 있다)
또한 각 파일로부터 반환된 jobs를 파이썬에 내장된 함수 open을 통해 생성해준다
이때 확장자는 csv , 모드는 w로 해준다
모드란? 파일을 열 때 어떤 형식으로 열지 정하는 것이다 w=write(쓰기), r=read(읽기), a=append(마지막에 추가하기)
CSV모듈 중 writer함수를 통해 제목, 회사명, 위치, 링크 순으로 각 위치에 리스트 형식으로 내용을 담아준다
우리가 반환한 인디드 값은 딕셔너리 형태이다
그렇게 된다면 스프레드시트에서 title: blablalba 이런 형태로 모든 것이 나오게 된다
이것을 없애기 위해 value함수를 통해 blablalba만 가져오자
작성한 코드
import csv
def save_to_file(jobs):
file = open("jobs.csv", mode="w")
writer = csv.writer(file)
writer.writerow(["title","company","location","link"])
for job in jobs:
writer.writerow(list(job.values()))
return
main.py에는 이런 식으로 인디드와 스택오버플로를 합쳐 저장했다
from indeed import get_last_pages
from so import get_jobs as get_so_jobs
from save import save_to_file
indeed_jobs = get_indeed_jobs()
so_jobs = get_so_jobs()
jobs = so_jobs + indeed_jobs
save_to_file(jobs)
이후 실행시켜보면
이런 형태로 jobs.csv에 저장이 된다
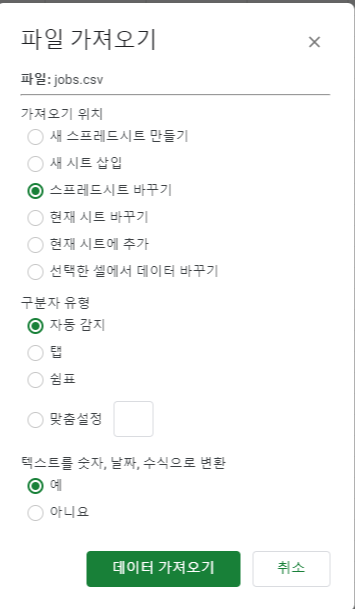
6.스프레드시트에 불러오기
Repl.it에서 모든 파일을 압축 형식으로 다운로드하여 자신이 알 수 있는 공간에 풀어준다
import requests
from bs4 import BeautifulSoup
result = requests.get(URL)
s = BeautifulSoup(result.text, "html.parser")
pagination = s.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
니꼬쌤은 import를 제외한 코드들을 함수로 쪼개는 편이 좋다고 한다
그 이유는 깔끔하니까
main.py는 가장 먼저 실행되는 메인 파일이다
니꼬쌤은 indeed.py를 만들어 코드를 작성했다
커다란 장농에 칸마다 종류별 옷들을 정리하는 것 같았다
그래서 이것을 get_last_pages라는 함수를 만들어 그 안에 넣었다
def get_last_pages():
result = requests.get(URL)
s = BeautifulSoup(result.text, "html.parser")
pagination = s.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
대부분의 함수는 전에 말했듯 반환해야 하는 값이 필요하다
우리가 찾고자하는 값은 마지막 페이지이므로 max_page를 반환 값으로 지정했다
이와 마찬가지로 제목과 회사, 위치, 링크의 각각의 태그들을 찾아준다
def extract_job(html):
title = html.find("div", {"class": "title"}).find("a")["title"]
company = html.find("span", {"class": "company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
location = html.find("div", {"class": "recJobLoc"})["data-rc-loc"]
job_id = html["data-jk"]
return {
"title": title,
"company": company,
"location": location,
"link": f"https://kr.indeed.com/%EC%B1%84%EC%9A%A9%EB%B3%B4%EA%B8%B0?&jk={job_id}"
}
extract_job함수로 모은 요소들
title = html.find("div", {"class": "title"}).find("a")["title"]
제목을 찾을 때 a태그의 문자열을 가져왔더니 문자열로 저장되지 않은 부분이 있었다
그래서 a태그 안에 있는 속성값 "title"로 구분을 해주었다
속성 값을 찾을 때는 [ ]로 표시한다
company = html.find("span", {"class": "company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
location = html.find("div", {"class": "recJobLoc"})["data-rc-loc"]